Phusion Passenger 5 (codename "Raptor") is a web server that's up to 4x faster than Unicorn, and up to 2x faster than Puma and Torquebox. Learn more about Phusion Passenger 5 here.
This blog post is part of a series of posts on how we've implemented Phusion Passenger 5.
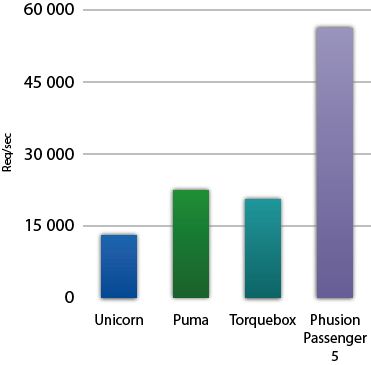
One of the big questions people have for us, is how we made Phusion Passenger 5 (codename “Raptor”) fast. Claiming that it’s “up to 4x faster” than other app servers is not a small claim, so in part 1 we’ve given an introduction into how Ruby app servers work, and we’ve described some of the techniques that we’ve used to make Phusion Passenger 5 fast. But there are a lot more techniques, which we’ll cover in this second blog post.
First, we’ll explain what CPU cache friendliness is and why it’s important, and we’ll describe micro-optimizations to achieve this.
Next, we’ll cover a special hash table that we’ve written for Phusion Passenger 5 in order to handle HTTP headers efficiently. We will discuss the various optimization strategies and the tradeoffs that we’ve made.
Then we’ll cover a feature called “turbocaching”, which is an integrated HTTP cache in Phusion Passenger 5. The turbocache can, in spirit, be seen as a “CPU L1 cache” for the web.
Finally, we’ll cover other miscellaneous optimization techniques such as caching time lookups and using persistent socket connections.
In this blog post:
In part 1, we’ve talked about the fact that RAM is much slower than CPU. CPU caches exist for this reason. CPU caches are small pools of very very fast memory located near the CPU, allowing the CPU to access it quickly and preventing RAM from slowing it down. They work by storing RAM data that the CPU has accessed recently, data that is accessed frequently, and data that the CPU may need in the future. Most computer algorithms follow these memory access patterns, which is why CPU caches are effective.
However, CPU caches are limited in size, so there’s only so much they can do. If a program accesses memory in a “strange” way, or if the program accesses so much memory in a short interval that they don’t fit in the CPU caches, then the CPU caches are ineffective and the CPU will be bottlenecked by RAM. ExtremeTech has an excellent article which describes CPU caches in detail.
Therefore, Phusion Passenger 5 tries to minimize the amount of memory that it needs. Part 1 has already described the zero-copy architecture and object pooling techniques which help in reducing memory usage, and thus increasing CPU cache effectiveness. However, we also utilize various micro-optimization techniques to further reduce memory usage.
Pointers are common elements in C and C++ data structures. A pointer is a reference to a certain memory address. They’re used to reference a particular object somewhere in memory. If you use Ruby then you’re using references everywhere. When you perform foo = Foo.new, then the foo variable contains a reference to a Foo object allocated in memory.
While pointers can conceptually be compared to references, pointers are more low-level. They’re actually like integers containing a memory address. In C and C++, you can manipulate the value of a pointer in arbitrary ways. Unlike references in Ruby, you can make a pointer that points to a random memory address, or maybe even to an invalid memory address (for example, to an object that has already been freed). This makes pointers very dangerous, but at the same time, also very powerful.
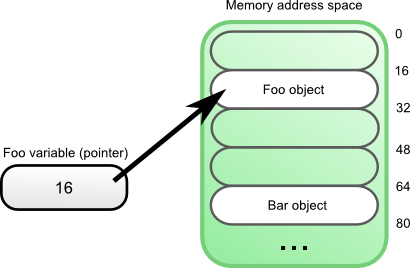
One of the powers granted by the low-levelness of pointers, is a technique called “pointer tagging”. It turns out that – on many popular platforms (including x86 and x86_64) – not all data stored in a pointer is actually used. That means that a pointer contains a bit of free space that we can use for our own purposes. A pointer in which we’ve inserted our own custom data is called a “tagged pointer”.
Why does a pointer contain free space? This has to do with data alignment. CPUs don’t like accessing data from arbitrary memory addresses. They would rather prefer to access data at memory offsets equal to some power-of-two multiple. For example, on x86 and x86-64, 32-bit integers should be aligned on a multiple of 32 bits (4 bytes). So an integer should be stored at memory address 0, or 4, or 8, or 12, …etc. On x86 and x86-64, accessing data at unaligned addresses results in a performance penalty. On other CPU architectures it’s even worse: accessing data at unaligned addresses would crash the program.
This is why the memory allocator always aligns the requested allocation. The size of the alignment depends on many different factors, and is subject to C structure packing rules. Suffice to say that, in the context of Phusion Passenger, the pointers that we tag refer to memory addresses that are aligned on at least a multiple of 4 bytes.
Being aligned on a multiple of 4 bytes has an interesting implication: it means that the lower 2 bits of a pointer are always zero. That’s our free space in the pointer: we can use the lower 2 bits for our own purposes.

2 bits isn’t a lot, but it’s enough to store certain state information. For example, each client in Phusion Passenger can be in one of 3 possible connection states:
enum ConnState {
/** Client object is in the server's freelist. No file descriptor
* is associated and no I/O operations are possible. From this state,
* it can transition to ACTIVE.
*/
IN_FREELIST,
/** Client object is actively being used. There's a file descriptor
* associated and no I/O operations are possible. From this state,
* it can transition to either DISCONNECTED or IN_FREELIST.
*/
ACTIVE,
/** Client object is disconnected, but isn't yet put in the freelist,
* because there are still references to the client object. No file
* descriptor is associated and no I/O operations are possible. The
* original file descriptor number is stored in fdnum for debugging
* purposes, but it does not refer to a valid file descriptor.
*/
DISCONNECTED
};
Because there are only 3 possibilities, this information can be represented in 2 bits – exactly the amount of free space available in a pointer.
In Phusion Passenger 5, connected clients are represented by Client objects. Client objects are created and managed by a Server object. Each Client object contains a pointer that points back to the Server that created it. This pointer is the perfect candidate for tagging.
So, instead of accessing a Client object’s connection state field directly, we access the field through a setter and a getter. The setter method stores the state information in the lower 2 bits of the server pointer:
void setConnState(ConnState state) {
// This code is not strictly conforming C++.
// It has been simplified to make it more
// readable.
// Clear lower 2 bits of the server pointer.
// 0x3 == 00000011 in binary.
server = server & ~0x3;
// Store state information in lower 2 bits
// with bitwise OR.
server = server | state;
}
The getter method extracts the state information from the lower 2 bits in the server pointer:
ConnState getConnState() const {
// This code is not strictly conforming C++.
// It has been simplified to make it more
// readable.
// Extracts the lower 2 bits from the server pointer.
// 0x3 == 00000011 in binary.
return server & 0x3;
}
Similarly, we can no longer access the server pointer directly. We also have a getter method that returns the server pointer with the lower 2 bits set to zero.
So how much memory do we save by using this technique? It depends, and the answer is complicated. Normally, saving the state information in its own field requires 1 byte of memory. However, in order to satisfy alignment requirements, C data structures are padded – i.e. certain memory is deliberately reserved but not used. The Client structure contains many pointers and integers, so on x86-64, Client objects have to be aligned on a multiple of at least 8 bytes (that’s how big pointers are). Depending on where exactly the field is inserted inside a structure, the field could increase the size of the structure by 8 bytes in the worst case (again, assuming x86-64; the specifics depend on the CPU platform).
In case of Phusion Passenger, the Client structure happened to be in such a way that we were able to save 8 bytes per Client object by storing the state information in a tagged pointer. Besides the Client structure, there are also other places where we apply this technique.
Granted, 8 bytes don’t seem much, but Phusion Passenger 5 is fast because we’ve accumulated a ton of these kinds of micro-optimizations. This technique by itself doesn’t help much, but it’s about all the optimizations combined. And because CPU caches are already so tiny, every bit of memory reduction is welcome.
It should be noted that pointer tagging is a platform-dependent (or in C standard jargon, “implementation defined”) technique. The way Phusion Passenger tags pointers doesn’t work on 16-bit platforms, because integers and pointers would be aligned on a multiple of 2 bytes, leaving only 1 bit of free space in pointers. On some platforms such as the Cray T90 system, pointers don’t work in the way we expect at all, making pointer tagging totally impossible. However nobody runs Ruby web apps on 16-bit platforms, and we haven’t seen anybody running Ruby web apps on “strange” platforms where pointer tagging is impossible. In this context, x86 and x86-64 are by far the most popular platforms, making pointer tagging a viable technique to use in Phusion Passenger.
Each field in a data structure takes up memory. But we might not need every field at the same time. Sometimes, certain fields are only accessed if the system is a certain state. For example, in Phusion Passenger we’re either parsing a client’s request headers, or we’re parsing its request body, or (if there is no body, and the headers have already been parsed) we’re doing neither. A naive implementation might store two pointers in the client structure: one that points to the header parser, and one that points to the body parser.
class Client {
...
HeaderParser *headerParser; // Pointer to a header parser object.
BodyParser *bodyParser; // Pointer to a body parser object.
...
};
In part 1, we’ve explained that parser objects are pooled, so they’re freed as soon as they become unnecessary. So when we’re parsing the body, there won’t be a header parser object alive at the same time. This is great, but we’re still wasting memory: the headerParser field still exists and still takes up 8 bytes of memory (assuming x86-64), even though we no longer need it. The two pointers together take up 16 bytes, even though we only need 8 bytes at once. How do we solve this problem?
Luckily, C and C++ support unions. A union is a language construct that allows us to define multiple fields that live in the same overlapping memory region. So in Phusion Passenger we’ve put both parser pointers in the same union:
class Client {
...
union {
HeaderParser *headerParser; // Pointer to a header parser object.
BodyParser *bodyParser; // Pointer to a body parser object.
} parser;
...
};
By putting both fields in a union, the two pointers together only take up 8 bytes, because their memory addresses overlap.
This technique is an excellent way to reduce memory usage, and we apply it whereever we can. But it’s also limited in usefulness and can be dangerous. Writing to a field automatically invalidates the content of another field in the same union, so it can only be used if you never have to access two fields at the same time, and only if you don’t care about persisting the value over multiple states. If you do it wrong then you would access garbage data, which may result in a program crash.
Just like pointer tagging, using unions is a micro-optimization. It doesn’t save you much, but Phusion Passenger is fast because we’ve gone through the pain of accumulating a ton of these kinds of micro-optimizations. All the small optimizations add up.
Hash tables are widely-used data structures for mapping keys to values. Hash tables are excellent for representing HTTP headers: most web servers use them to map HTTP header fields to their values. On average, hash tables provide lookup, insertion and removal in O(1) time. For most workloads, they’re faster than binary trees. In Ruby, hash tables are provided by the Hash class.
However, in the context of a web server, we’ve found that off-the-shelf hash table implementations leave open a lot of optimization opportunities. Given Phusion Passenger’s workload, off-the-shelf hash tables don’t manage memory optimally. For this reason, we’ve written our own highly optimized hash table, specifically designed for storing HTTP headers.
Hash tables can be implemented in multiple ways. The most popular approach is chaining with linked lists. The hash table consists of a number of buckets. When an element is inserted into the hash table, the hash table looks up the corresponding bucket, and appends the element to the linked list inside that bucket. This approach is easy to implement and is used by Ruby, by most C++ standard library hash table implementations, and by most third-party hash table implementations.
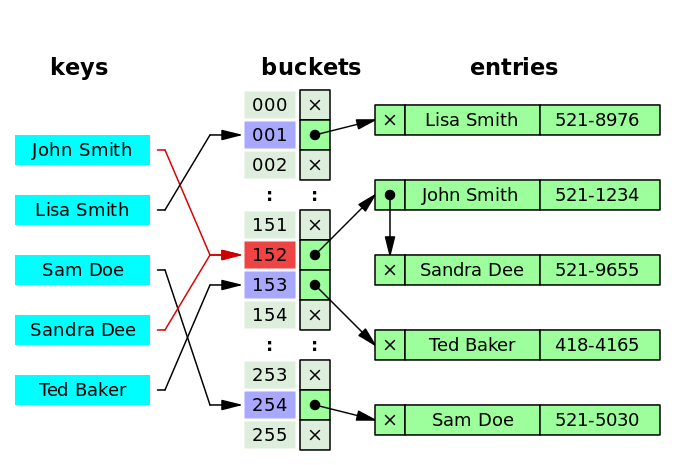
However, there are several problems with the chaining approach:
There are two ways to solve these problems:
Both ways are equally valid, but we’ve chosen to go for the open addressing approach because we’ve found a library to base our custom hash table on: the integer hash map by Jeff Preshing. Preshing originally wrote this library to demonstrate that hash tables can be faster than Judy arrays (which is a very complex data structure that is supposed to be faster than hash tables by being more CPU cache friendly). His library was simple, easy to understand and to modify, and had the right license.
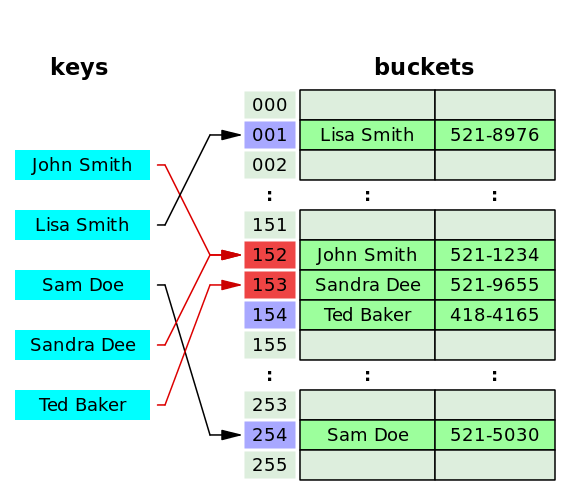
The Phusion Passenger hash table uses linear probing: hash conflicts are resolved by scanning the next item in the bucket array. Although quadratic probing and double hashing are less vulnerable to clustering (lots of elements with conflicting hash values stored near each other), they are also less CPU cache friendly because their memory access patterns are irregular. The Phusion Passenger hash table is designed to store HTTP headers, and most HTTP requests tend to have 10-20 headers. Clusters don’t tend to be very big. Thus, we’ve chosen linear probing for its CPU cache friendliness.
After every request, we clear the hash table because the headers in the next request can be totally different. Most hash table implementations implement this clearing by freeing all memory that it has allocated. This is suboptimal: memory deallocation is expensive, and it would just mean that we need to allocate memory again during header parsing.
The Phusion Passenger hash table implementation allows memory reuse. Instead of freeing the bucket array, we simply mark each entry as “unused”. This is much faster than deallocating and reallocating memory.
The Phusion Passenger hash table maps strings (HTTP header names) to strings (HTTP header values). Strings are variable-sized, so we can’t store them in the hash table directly. We already know that we shouldn’t store strings on the heap because that’s expensive, so we store strings in the palloc pool. The hash table merely contains pointers to the strings. The palloc pool ensures that strings are allocated nearby each other, greatly benefiting CPU cache locality.
However, there’s one problem: we might not receive a complete HTTP header in a single socket read call. We might receive the complete HTTP header data over multiple socket read calls. For example, suppose you receive the data Content-Type: te in one call, and then you receive xt/plain\r\nFoo: bar\r\n\r\n in another call. Most software solves this problem in one of two ways:
Content-Type: te and xt/plain\r\nFoo: bar\r\n\r\n together in a single contiguous buffer. Upon encountering \r\n\r\n, it would parse the entire buffer in a single pass.Content-Type element into the hash table, with value te. During the second iteration, it would notice that xt/plain is a continuation of the previous header, so it would append this into the te string, after which it inserts Foo => bar into the hash table.But both approaches work by appending to an existing buffer/string, with the goal of forming a new, single, contiguous buffer/string. This has two implications:
This is why we use linked strings throughout the Phusion Passenger codebase, including the hash table. The idea is that, instead of working with contiguous strings and going through the trouble of making everything contiguous, we make everything work correctly with non-contiguous strings. A linked string is simply a string data structure represented by a linked list.
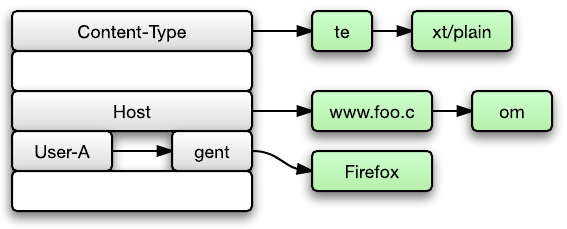
The most important operations are appending and comparing.
So by using linked strings instead of contiguous strings, we avoid unnecessarily copying strings around, saving precious CPU cycles and memory.
Because almost all hash table operations require a hash of the key, it’s beneficial to pre-calculate key hashes ahead of time, instead of recalculating the hash on every operation. Most hash table libraries don’t allow using precalculated hashes, and insist on recalculating the hash every time, but Phusion Passenger’s hash table allows it. Because our lookups are limited to a few predefined headers, e.g. the Host header, the Date header, the Content-Type header, etc, it’s rather easy for us to precalculate key hashes. This drastically reduces the amount of time spent on hash table operations.
We’ve also investigated the Google sparsehash and densehash library as an alternative to implementing our own. Sparsehash is a special hash table implementation that uses very little memory for unused bucket elements (at the expense of more CPU usage), while Densehash is a hash table library optimized for performance (at the expense of more memory). Unfortunately, neither libraries turned out to be suitable for Phusion Passenger. They do not manage memory optimally, they do not allow bucket memory reuse and they do not allow precalculation of hashes. These libraries have been dropped in favor of implementing our own hash table.
When it comes to improving performance and scalability, applying caching is standard practice. Caching is relatively easy to apply, and the benefits can be large. Caching can accelerate a web app tremendously.
However, utilizing caching in web apps often requires some setup. For example, you may have to install and configure Memcached or Redis for key-value caching, and you may have to install and configure Varnish for HTTP caching. The current situation makes it very clear that caching is external and “bolted on”.
There’s nothing really wrong with external caching systems per se: Memcached, Redis and Varnish are very powerful and very mature. However, there are issues:
This is why Phusion Passenger comes with an integrated HTTP cache, which we call the turbocache. The turbocache is a first-line HTTP cache. It is simple, it has a small capacity, it has a limited set of features, but it’s very very fast. The turbocache does not seek to replace external HTTP caching systems like Varnish. Think of the turbocache, in spirit, as a “CPU L1 cache” for the web: by itself the turbocache is already very useful and provides a first-line performance improvement, but for more advanced caching scenarios you can easily combine it with a dedicated caching system like Varnish to get the best of both worlds.
Because the turbocache is so simple, and because it’s integrated into Phusion Passenger’s HTTP server, it is much faster than Varnish. The turbocache is implemented in C++ and is highly optimized, so it’s even faster than in-process Ruby HTTP caches like rack-cache.
Turbocaching is turned on by default, but it can optionally be turned off.
The turbocache is a regular HTTP cache, so it works by examining response headers and caching response data. If a request can be satisfied with an entry in the turbocache, then Phusion Passenger will send the cached response without ever touching the application. This greatly improves performance.
As an application author, you do not need to use Phusion Passenger-specific APIs to take advantage of turbocaching. Simply set your HTTP response headers right, and it’ll work automatically with Phusion Passenger’s turbocache, with the browser’s cache, and with any other HTTP cache. Setting proper HTTP caching headers is supported by virtually any web framework. There is a ton of documentation on HTTP caching, such as Google’s Web Fundamentals guide.
The turbocache’s design is inspired by that of CPU caches. The turbocache is not a hash table that can grow, as one would usually use for implementing software caches. Neither is the turbocache backed by disk. Instead, the turbocache is a fully in-memory data structure with statically defined limits. These static limits make it possible to perform certain CPU cache friendliness optimizations.
The turbocache is a fully associative cache, with a maximum size of 8 entries. Each entry logically contains a key, the key’s hash, the cached response body, and various other information such as the timestamp. A lookup involves creating a key and calculating its hash, and scanning linearly through all the entries.
The maximum size of 8 and the choice of linear scanning have been chosen deliberately. With a size of 8, the turbocache fits in exactly 2 CPU cache lines, or 128 bytes. Because of the small size and the CPU cache friendliness, it makes linear scanning a suitable algorithm for lookups, as will be described later.
The CPU cache friendliness of the turbocache can only be guaranteed if it’s compact enough. An important technique that we use to achieve this, is hot-cold separation.
The turbocache is separated into two arrays, one containing cache entry headers, and one containing cache entry bodies. The cache entry headers consist of “hot” data – data that is accessed very often. During a lookup, the linear scan only accesses data in the cache entry headers (comparing keys, comparing timestamps). Only when an entry has been found to match the lookup criteria will the corresponding cache entry body be accessed as well. Thus, the cache entry body isn’t accessed as often, and can be considered “cold” data.
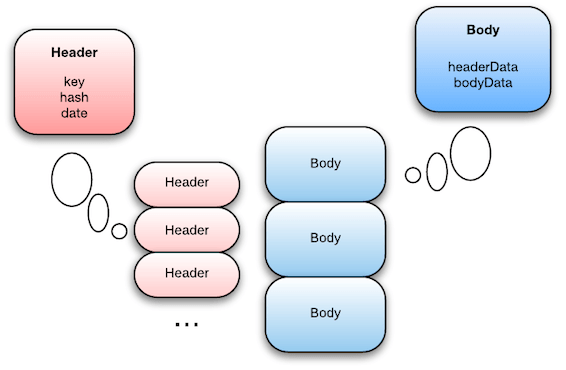
By clustering hot data together, the number of CPU cache lines that the linear scan has to go through is reduced. This allows the linear scan to work quickly and with fewer cache misses. As you can see in the diagram, the cache entry body is also much larger than the cache entry header, so if the body was stored near the header then the linear scan will have to jump through a lot of “holes”, making CPU caching less effective.
The turbocache uses linear scanning to lookup a cache entry. Despite its seemingly unfavorable algorithmic complexity, data structures are deliberately kept small in order to make linear scanning a viable algorithm. Although linear scanning is O(N), if N is small enough then linear scanning can be faster than more sophisticated algorithms that have better algorithmic complexity. Linear scanning is not only CPU cache friendly, but it is also friendly to the CPU branch predictor. Modern Intel CPUs even have specialized circuits to run small loops – like those of linear scans – more quickly.
The linear scan is further sped up through the use of the 32-bit hash: instead of comparing the key on every scan, we first compare the hash. This has two advantages:
We do not use binary search because using that algorithm requires us to keep the cache in a sorted state, which has an algorithmic complexity of O(N * log(N)). Binary search is also less CPU branch prediction friendly than linear search.
There may still be room for future improvements. We can make the turbocache more like an open addressed hash table that cannot grow and that overwrites old entries. Due to time constraints, we’ve not been able to explore this option, so it’s not yet clear whether this would significantly improve performance. Nevertheless, the current linear scan design is already very fast.
Upon storing a new cache entry into a turbocache that is full, the turbocache will evict the oldest entry. This Least-Recently-Used policy of cache eviction is very simple, but has proven to be very effective in practice.
Due to the speed and small size of the cache, the turbocache is best at handling large bursts of traffic to a small number of end points. If you have bursts of traffic to many different end points, then you should combine Phusion Passenger with a dedicated caching system like Varnish.
Unlike Unicorn and Puma, the Phusion Passenger HTTP server – the entity which accepts client requests – does not run inside the Ruby application process. Instead, this server (internally called the request handler) runs in its own process, outside the Ruby application. There are various reasons why this is the case, some of which are related to performance characteristics, some of which are related to stability guarantees. A detailed discussion of the reasons is outside the scope of the article. But the main point is that, because of the separation, we need some kind of inter-process communication channel so that the request handler and the application processes can talk to each other.
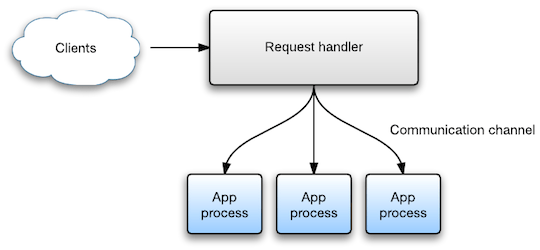
What kind of communication channel is suitable? The most obvious candidate is regular TCP sockets, which provide raw byte streams between end points. TCP sockets not only work over the Internet, but also locally. The Linux kernel even has special optimized code paths for dealing with local TCP sockets – TCP sockets that connect two local end points. Many Puma and Unicorn setups use TCP sockets to connect themselves with a reverse proxy (like Nginx).
TCP sockets are great and work fine, but there is a better alternative: Unix domain sockets. Unix domain sockets also provide raw byte streams between two end points, but the two end points have to live on the same machine, under the same OS. Unix domain sockets are much faster than local TCP sockets, because you avoid the entire TCP/IP stack. TCP sockets work with IP addresses and ports; Unix domain sockets work with filenames. A Unix domain socket is an actual file on the filesystem!
Puma and Unicorn can also be setup to listen on Unix domain sockets, and Nginx can be configured to proxy to Unix domain sockets. Some Puma and Unicorn tutorials recommend this for performance reasons.
In Phusion Passenger, we’ve chosen to avoid the option of TCP sockets altogether. This doesn’t mean that Phusion Passenger talks to the Internet through Unix domain sockets; the request handler, which talks to clients, still supports TCP sockets. But for local communication between the request handler and application processes, we use only the most optimized communication channel: Unix domain sockets. We believe that this is good design because it makes Phusion Passenger fast by default. Users should not have to tweak Phusion Passenger to get more performance: performance should be turned on out-of-the-box.
One notable optimization that we’ve added on top of Unix domain sockets, is that of persistent connections. This is an optimization that is rarely used in setups with Puma/Unicorn + Nginx.
In most Puma/Unicorn + Nginx setups, Nginx creates a new connection with Puma/Unicorn for every incoming request. The connection is closed when the request finishes. This happens no matter whether Puma/Unicorn are setup with TCP sockets or Unix domain sockets. However, this introduces an inefficiency. Creating a new connection is not free and takes some time. It requires a system call, which performs a context switch to the kernel and pollutes CPU caches. The kernel also has to allocate various resources for the connection.
In contrast, Phusion Passenger stores connections in a pool. Instead of closing the connection, Phusion Passenger simply returns the connection to the pool so that it can be reused next time Phusion Passenger needs a connection to an application process. Because the pool is implemented within Phusion Passenger, checking out a connection from the pool does not require a system call. This prevents a context switch to the kernel and prevents CPU cache pollution.
While it is possible to utilize this optimization in Puma/Unicorn + Nginx setups, Phusion Passenger provides this optimization by default. Our philosophy is that users should not have to tweak Phusion Passenger to get more performance.
One of the operations that Phusion Passenger performs frequently, is looking up the current time. Many actions require knowing what the current time is: expiring caches, generating response timestamps, and so forth. Surprisingly, time lookup is relatively expensive. On many operating systems it requires a system call, which switches context to the kernel and pollutes CPU caches. Profiling reports often point to time lookup as a significant hot spot.
We realized that we do not always need to know the exact time: we just need to know the approximate time, give or take a few milliseconds. This means that we can cache time lookups. But this cache cannot use time-based eviction: doing so would introduce a chicken-or-egg problem.
Luckily, the libev event loop library which Phusion Passenger uses has a builtin time cache. The time is looked up at the beginning of an event loop iteration, and is cached for the rest of that iteration. Because the time lookup is performed nearby other system calls (such as the event loop multiplexor system call), the ill effects of CPU cache pollution by switching to the kernel are minimized.
In this blog post we’ve introduced many more optimization techniques that we’ve used in Phusion Passenger 5 (codename “Raptor”). But despite all the focus so far on performance, Phusion Passenger’s strength doesn’t solely lie in performance. Phusion Passenger provides many powerful features, makes administration much easier and lets you analyze production problems more quickly and more easily. In future blog posts, we’ll elaborate on Phusion Passenger’s features.
If you haven’t read part 1 yet then you may want to do so. In part 1 we’ve given an introduction into how Ruby app servers work, and we’ve covered subjects such as the Node.js HTTP parser, the hybrid evented/multithreaded architecture, zero-copy mechanisms, and various method to avoid memory allocations.
We hope you’ve enjoyed this blog post, and we hope to see you next time!
If you like this blog post, please spread the word on Twitter. :) Thank you.
This blog post is part of a series of posts on how we've implemented Phusion Passenger 5 (codename "Raptor"). You can find more blog posts on the Phusion blog. You can also follow us on Twitter or subscribe to our newsletter. We won't spam you and you can unsubscribe any time.