

Phusion Passenger 5 (codename "Raptor") is a web server that's up to 4x faster than Unicorn, and up to 2x faster than Puma and Torquebox. Learn more about Phusion Passenger 5 here.
This blog post is part of a series of posts on how we've implemented Phusion Passenger 5.
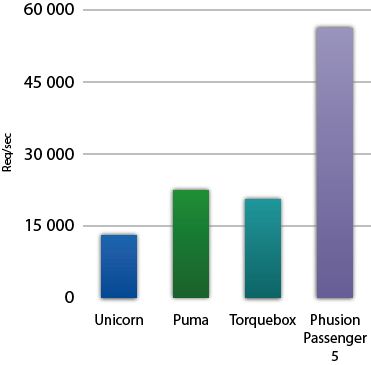
The following people have kindly contributed translations for this article:
Part 2 is now available: Pointer tagging, linked string hash tables, turbocaching and other Phusion Passenger 5 optimizations
One of the big questions people have for us, is how we’ve made Phusion Passenger 5 (codename “Raptor”) fast. After all, claiming that it’s “up to 4x faster” than other app servers is not a small claim. Unicorn, Puma and Torquebox are already pretty fast, so beating them hasn’t been easy and has taken a lot of work.
There are multiple reasons why Phusion Passenger 5 is fast, and we will release a series of blog posts that explain in high detail the techniques used to make a fast application server. In future blog posts we’ll also elaborate more on Phusion Passenger 5’s advanced features, because performance isn’t the only thing that Phusion Passenger 5 is good at.
First, we’ll give an introduction into how Ruby app servers work. This places our optimization techniques in the right context. Next, we’ll cover some of the optimization techniques, namely the usage of a fast HTTP parser, combining multithreading and evented I/O, zero-copy architecture and memory allocation techniques.
The work that we’ve done to make Phusion Passenger 5 fast is fairly low-level, so a good understanding of sockets, networking, operating systems and hardware would help a lot with making sense of this article. We’ve provided some resources in the Literature section so that you can gain a better understanding of these mechanisms.
In this blog post:
But before we go into the hardcore details, here’s a conceptual introduction into Ruby app servers. If you’re already familiar with this material, you can skip this section.
All Ruby app servers are essentially HTTP servers, because HTTP is the universal protocol that all Ruby app servers speak. Maybe you have a vague understanding of what an HTTP server is. But what does it really do, and how does it fit in the overall picture with the application?
All web applications follow a basic model. First, they have to accept HTTP requests from some I/O channels. Then they process these requests internally. Finally, they output HTTP responses, which are sent back to the HTTP clients. The clients are typically web browsers, but may also be tools like curl or even search engine spiders.
However, Ruby web apps don’t typically work with HTTP requests and responses directly, because if they do then each Ruby web app would have to implement its own web server. Instead, they work with an abstraction of HTTP requests and responses. This abstraction is called Rack. Every Ruby app server implements the Rack abstraction, while Ruby web frameworks like Rails, Sinatra etc interface with the app server through the Rack specification. This way, you can seamless switch between app servers: switching from Puma or Unicorn to Phusion Passenger 5 is trivial.
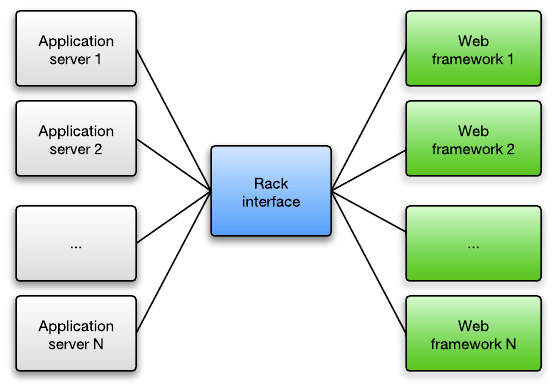
So the job of the app server is to accept and parse HTTP requests, to speak with the underlying web app through the Rack abstraction, and to convert the Rack responses (which the application returns) back into real HTTP responses.
When writing network software (like HTTP servers), there are multiple I/O models that the programmer can choose from. The I/O model defines how concurrent I/O streams are handled. Each model has its own pros and cons. The Rack specification does not specify which I/O model is used. That is left as an implementation detail of the application server.
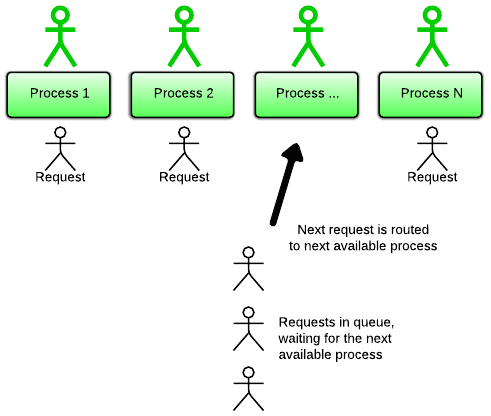
A read call blocks if the other side hasn’t sent any data yet, and a write call blocks if the other side is too slow with receiving data. Because of the blocking behavior, an application can only handle 1 client at a time. So how do we handle more clients at a time? By spawning multiple processes!
This I/O model is the traditional model used by Ruby web apps, and is the one used in Unicorn, as well as Apache with the prefork MPM.
Pros:
Cons:
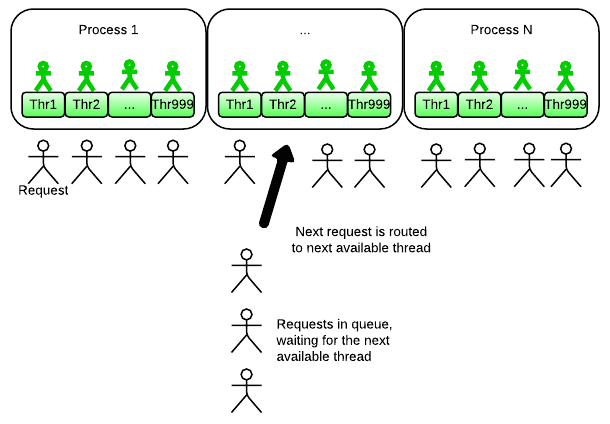
I/O calls still block, but instead of only spawning processes, the app server also spawns threads. A process has multiple threads, and each thread handles 1 client at a time. Because threads are lightweight, you can handle the same amount of I/O concurrency with a lot less memory. To serve 5000 websocket clients, you need 5000 threads in total. Suppose you run 8 app processes on your 8-core server (1 process per CPU core), then each processes must be configured with 625 threads. Ruby and your OS can handle this easily. A single process would use maybe 1 GB of memory (assuming a 1 MB overhead per thread), but probably less. You’ll only need 8 GB of memory in total, a lot less than the 1.2 TB when using the multi-process blocking I/O model.
This I/O model is the one used Torquebox and by Apache with the worker MPM. It’s also used by Puma, for the most part; Puma uses a limited hybrid strategy, which we’ll describe later.
Pros:
Cons:
I/O calls do not block at all. When the other side hasn’t sent data yet, or when the other side is too slow with receiving data, I/O calls would just return with a specific error. The application has an event loop which contiuously listens for I/O events and responds to them accordingly. The event loop sleeps when there are no events.
This I/O model is by far the “weirdest” one and the one that’s the hardest to program against. It requires an entirely different approach than the previous two. While multi-process blocking I/O code can be fairly easily turned into multi-threaded blocking I/O code, using evented I/O often requires a rewrite. The application must be specifically designed to use evented I/O.
This I/O model is the one used by Nginx, Node.js and Thin. It’s also used partially by Puma for limited protection against slow clients; we’ll describe this later.
Pros:
Cons:
What are “slow clients” and why can they pose a problem? Imagine your application as the city hall, and your app server as the city hall desks. People enter a desk (send a request), do some paper work (processing inside the app) and leave with stamps on their papers (receive a response). Slow clients are like people entering a desk, but never leaving, so that the clerk can not help anybody else.
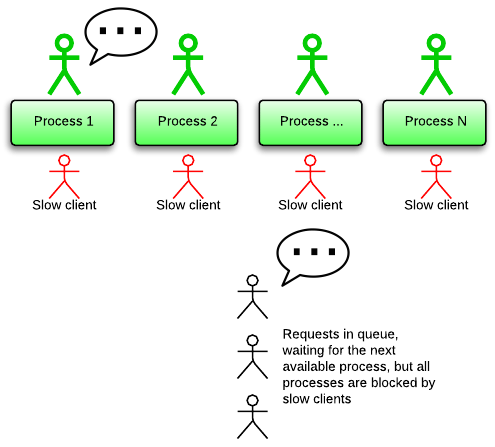
Are slow clients a real problem? In a word: yes. Slow clients used to be modem users, but nowadays slow clients can also be mobile clients. Mobile networks are notorious for having high latency. Network congestion can also cause clients to become slow. Some clients are slow on purpose in order to attack your server: see the Slowloris attack.
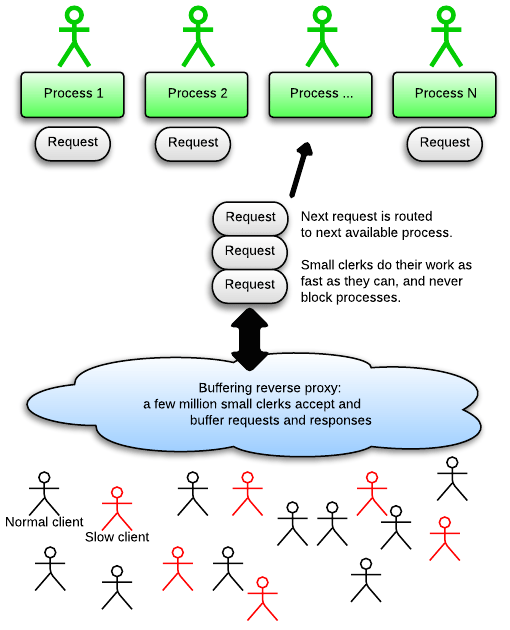
This problem is solved with a buffering reverse proxy that can handle a much larger I/O concurrency. Imagine that we put a million clerks outside the building. These clerks are not trained to process your paperwork. Instead, they only accept your paperwork (buffer your requests), bring them to the clerks inside the city hall, and bring the stamped paperwork back to you (buffer application responses). These clerks never stand still in front of the desks so they’ll never cause the slow client problem. Because these outside clerks are lightly trained, they’re cheap (use less RAM) and we can have a lot of them.
This is why Eric Wong, author of Unicorn, urges people to put Unicorn behind a buffering reverse proxy. This buffering reverse proxy is usually Nginx, which buffers everything and can handle a virtually unlimited number of clients. Multithreaded servers like Puma and Torquebox are less susceptible because they have more desks inside the city hall, but those desks are still limited in number because the clerks require more training (use more RAM) compared to the cheap clerks outside the building.
Phusion Passenger 5 uses all three of the aforementioned I/O models. Phusion Passenger 5 uses a hybrid strategy in order to fight the slow client problem. By default, Phusion Passenger 5 uses the multi-process blocking I/O model, just like Unicorn. However, Phusion Passenger 5 has a built-in buffering reverse proxy. This builtin reverse proxy is written in C++ and uses evented I/O.
Why is a builtin buffering reverse proxy cool? Why not rely on Nginx?
In other words: it’s all about making things simple.
Puma also uses a similar hybrid strategy. It’s multithreaded but has a builtin evented server which buffers requests and responses. However, Puma’s implementation is limited, and only protects against slow sending clients, but not against slow receiving clients. Phusion Passenger 5’s implementation fully protects against slow clients, no matter in which direction they’re slow.
Phusion Passenger 5 also optionally allows multithreading in a future paid version. The core of Phusion Passenger 5 is open source, as are most features, but specific features like multithreading will be available in a paid manner. We’ll release more information about this later. When multithreading is enabled, the app is still protected by the builtin buffering reverse proxy, so it’s not necessary to attach it behind Nginx.
With the introduction out of the way, it’s time for the hardcore details: how we’ve made Phusion Passenger 5 fast. The performance is mostly thanks to our HTTP server implementation. We’ve written a custom, embedded HTTP server in C++, completely optimized for performance.
The builtin HTTP server is about twice as fast as Nginx. This is because it’s completely designed for the workloads that Phusion Passenger 5 handles. In return, it has fewer features than Nginx. For example, our builtin HTTP server doesn’t handle static file serving at all, nor gzip compression. It trades features for performance. Having said this, you can still enjoy all the Nginx features by proxying Phusion Passenger 5 behind Nginx, or by direct Nginx integration. This is fully supported and it’s something that we will elaborate on in a future blog post.
This builtin HTTP server is also our builtin buffering reverse proxy, as described in section “The slow client problem”.
Our builtin HTTP server utilizes the Node.js HTTP parser, which is written in C. The Node.js HTTP parser is based on the Nginx HTTP parser, but it has been extracted and made general, so that it can be used outside the Nginx codebase. The parser is quite nice and supports HTTP 0.9-1.1, keep-alive, upgrades (like websockets), request and response headers and chunked bodies. It is quite robust and correctly handles parsing errors, which is important from a security perspective. Performance is quite good as well: the data structures are optimized in such a way that they use as little memory as possible, can be used in a zero-copy manner, while still being general enough to be used in all sorts of applications.

There are other options that we’ve considered as well. First is the Mongrel parser, originally written by Zed Shaw for Mongrel. Zed used Ragel to automatically generate a parser in C using the HTTP grammar specification. This parser has proven to be very successful and robust, and is also used in Thin, Unicorn and Puma. However we chose not to use this parser because it’s very Ruby-oriented. Although it’s C code, it accesses a lot of Ruby internals, making it hard to use outside of Ruby. It’s also less performant than the Node.js parser.
PicoHTTPParser is the HTTP parser used in the H2O embedded web server. The author claims that it’s much faster than the Node.js HTTP parser, but it’s also less battle tested. H2O hasn’t quite proven itself in production yet, while the Nginx HTTP parser has been around for a long time, and the Node.js parser has also received quite some testing thanks to the popularity of Node.js. HTTP parsing is one of the most important parts of an HTTP server, and doing anything wrong here can at best result in incorrect behavior, and at worst result in security vulnerabilities. Since Phusion Passenger 5 aims to be a production-grade server, we’ve chosen the slightly slower but likely more battle-tested Node.js HTTP parser over PicoHTTPParser.
We’ve also considered hand-rolling our own HTTP parser. However, this would be a tremendous undertaking, would put the burden of maintenance on ourselves, and wouldn’t be as battle-tested as the Node.js parser. In short, the reasons why we chose the Node.js parser over hand-rolling our own is very similar to the reasons why we chose not to use PicoHTTPParser.
As mentioned before, our builtin HTTP server is evented. Writing a network event loop with support for I/O, timers, etcetera is quite a lot of work. This is further complicated by the fact that every operating system has its own mechanism for scalable I/O polling. Linux has epoll, the BSDs and OS X have kqueue, Solaris has event ports; the list goes on.
Fortunately, there exist libraries which abstract away these differences. We use the excellent libev library by Marc Lehmann. Libev is very fast and provides I/O watchers, timer watchers, async-signal safe communication channels, support for multiple event loops, etc.
Libev should not be confused with the similarly-named libevent. Libevent is also an excellent library and is much more full-featured than libev. For example, it also provides asynchronous DNS lookups, an RPC framework, a builtin evented HTTP server, etc. However, we don’t need any of those extra features, and we were confident that we can make an HTTP server that’s faster than the libevent builtin HTTP server. We’ve also found libev to be faster than libevent thanks to libev’s smaller feature set. This is why we’ve chosen to go with libev instead of libevent.
When we said that Phusion Passenger 5’s builtin HTTP server is evented, we were not telling the entire truth. It is actually hybrid multithreaded and evented. Our HTTP server spawns as many threads as the number of CPU cores, and runs an event loop on each thread.
The reason why we did this is because evented servers are traditionally bound to a single CPU core. We’ve found that by using a single CPU core, Phusion Passenger 5 was not able to make full use of the system’s resources. Therefore we’ve chosen a hybrid strategy.
However, our original hybrid approach posed a problem. Threads could become “unbalanced”, with one thread (and thus one CPU core) serving a majority of the clients while the other threads served only a small number of clients. The load would not be evenly distributed over CPU cores. Upon further investigation, it turned out that the evented nature of the threads was the culprit: a thread would accept multiple clients before the kernel schedules another thread. By the time the scheduling happens, the first thread has already accepted the majority of the clients. This is a problem that doesn’t occur with traditional blocking multi-process/multithreaded servers, because each process/thread would only accept the next client when it’s done processing the client request.
We solved this problem by writing an internal load balancer, which is responsible for accepting new clients and distributing them evenly over all threads in a round-robin manner.
CPUs have become faster and faster, but RAM speeds have been lagging behind for more than a decade. Accessing RAM can cost thousands of CPU cycles. Because of this, CPUs have multiple layers of memory caches, which are very small but very fast. But because of the small cache sizes, high-performance applications should minimize their working set – the amount of memory that they use in a given short time interval.
The main job of an HTTP server is to process I/O, so naturally this means that it has to manage memory buffers for I/O operations. However, memory buffers are fairly large compared to CPU cache sizes. 4 KB is a typical size for such memory buffers. In comparison, most CPUs have an L1 cache of 32 KB or less.
A naively written HTTP server might manage the life times of I/O data by copying them between multiple buffers. However, this puts even more stress on the small CPU caches. Thus, a high performance HTTP server should minimize the amount of data copying.
Phusion Passenger 5 is completely built with a “zero-copy architecture”, which means that we completely avoid copying memory buffers when it’s not necessary. Such an architecture reduces the working set and reduces stress on CPU caches. Two subsystems form the core of our zero-copy architecture: mbufs and scatter-gather I/O.
Network software receive data over sockets through the read() system call. This system call places data in a specified buffer. One important question is: where does this buffer come from?
The buffer can be allocated on the stack. Stack allocation is very very fast because it only involves bumping a pointer, but it means that the buffer only lives until the end of the function in which the buffer is defined. This means that all operations on that buffer must finish before the receiver function returns. This is viable when using blocking I/O, but not viable when using evented I/O. Operations are fully asynchronous and may outlive the receiver function. When using stack allocation, one must therefore copy the buffer to keep it alive.
The buffer can also be allocated on the heap when a client connects, and freed when that client disconnects. This decouples the life time of the buffer from the life time of the receiver function. However, heap allocation is expensive and would kill performance.
We’ve eventually found the silver bullet in the form of a system of heap-allocated, but reusable memory buffers. Instead of freeing a buffer, it’s merely put in a freelist. Next time we need a buffer, we take one from the freelist when available, or allocate one when not available. Over time, this completely eliminates the overhead of allocating buffers on the heap. This system is called mbuf. It is based on the mbuf system in Twitter’s twemproxy, but we’ve made several important modifications:
read() call.There are a few downsides to this approach. One is that memory buffers are never released back to the operating system automatically, because doing so might hurt performance. Therefore, when left alone, Phusion Passenger 5’s memory usage would be proportional to the peak number of clients. Luckily, we also provide an administration command so that the administrator can force free memory buffers to be released back to the operating system.
The other downside is that, since mbufs are private to a thread, threads cannot reuse each others’ free memory buffers. This could lead to slightly higher memory usage than is necessary.
Normally when you have strings from multiple memory addresses, and you want to write them over a socket, you have two choices:
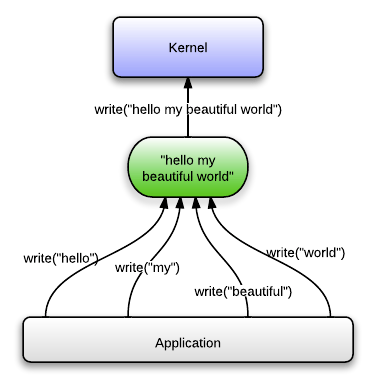
In a similar fashion, if you want to read some data from a socket but you want different parts of the data to end up in different memory buffers, then you either have to read() the data into a big buffer and copy each part to the individual buffers, or you have to read() each part individually into its own buffer.
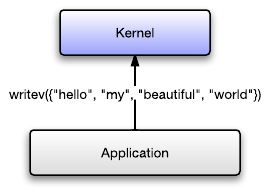
With scatter-gather I/O you can pass an array of memory buffers to the kernel. This way you can tell the kernel to write multiple buffers to a socket, as if they form a single contiguous buffer, but with only one kernel call. Similarly you can tell the kernel to put different parts of the read data into different buffers. On Unix systems this is done through the readv() and writev() system calls. Phusion Passenger 5 uses writev() extensively.
 </a>
</a>Dynamic memory allocation using the C malloc() function or the C++ new operator is expensive. Especially in an HTTP server, dynamic memory management can easily eat a major part of the processing time. Depending on the memory allocator implementation, it can also be significant source of lock contention between threads. This is why we use per-thread object pooling and region-based memory management.
Why is dynamic memory allocation expensive? Allocating and freeing memory might seem like simple operations, but in reality they have rather complex logic that can be slow. It turns out that allocating and freeing memory is a complex problem. Therefore, dynamic memory allocation should be avoided in high-performance applications. Avoiding memory allocation is standard practice in high-performance game programming.
Since memory allocated by one thread can be freed by another, dynamic memory allocators have global data structures which are protected by locks. This automatically means that threads contend on a lock when they allocate or free memory at the same time. Some dynamic memory allocator implementations, like Google’s tcmalloc, implement per-thread caches which improves the situation somewhat, but the problem of lock contention is never fully solved.
One solution to these problems is to allocate objects on the stack. However, just like with buffers, this is only useful in a limited number of cases. We may want an object to live longer than the scope of a function.
Therefore we use two techniques to avoid dynamic memory allocations: object pooling and region-based memory management.
Object pooling is a technique similar to the one we used for mbufs. We put free objects in a freelist when we no longer need them. When we need a new object again, we just take one from the freelist (or allocating one when the freelist is empty), which is a fast O(1) operation involving changing a few pointers.
Unlike mbufs, which are allocated on the heap, pooled objects are allocated from segregated storage using the excellent boost::pool library. With boost::pool, we allocate large chunks of memory, which we then divide into small pieces equal to the object size, and objects are allocated from these memory chunks. This has two further advantages:
We apply the pooling technique to client objects, request objects, HTTP parser objects, body parsing objects and application session objects. These objects are created very frequently, and therefore benefit greatly from pooling. Client objects are created every time a client connects, while request-, HTTP parser- and application session objects are created on every request.
While writing Phusion Passenger 5, we also came to the realization that this technique can be used for more than just avoiding memory allocations: it can also be used for minimizing memory usage. For example, we need the HTTP parser object on every request, but not during the entire lifetime of the request. So instead of embedding the HTTP parser object as a static object inside the client object, we can allocate it dynamically from the pool, and free it when we no longer need it, without harming performance.
The disadvantages of object pooling are very similar to the disadvantages of mbufs. Free memory is never automatically released back to the operating system. Object pools are per-thread so that threads cannot share objects, resulting in slightly higher memory usage than necessary.
Besides objects, the Phusion Passenger 5 HTTP server also needs to allocate miscellaneous variable-sized data structures and strings during request processing. For example, it needs to allocate variable-sized arrays in order to keep track of buffers. It needs to allocate small buffers in order to format strings, like generating timestamp strings. It needs to allocate hash tables and associated entries in order to keep track of header fields and values.
Object pooling is useful for fixed-size objects, but not for variable-sized structures. Again, stack allocation is only of limited use because of lifetime issues. Mbufs are also not useful for these structures because mbufs have a fixed size. If the mbuf size is too small, then the structure cannot be allocated inside it. If the mbuf size is too big, then memory is wasted. This makes mbufs only useful as buffers for I/O operations. And because of the variable sizes, we can’t pre-allocate static storage inside client and request objects.
The palloc subsystem in Phusion Passenger 5 solves this problem in an elegant way. It is an implementation of region-based memory management. We allocate a 16 KB chunk of memory that’s associated with the request. This chunk of memory is used like a stack, for allocating small structures and strings. Allocation is extremely fast because it only involves bumping a pointer. But unlike the system stack, the palloc stack pointer is never decremented: you can only allocate, not deallocate. The stack pointer is reset back to 0 at the end of the request, making the entire memory chunk reusable again. If more memory is needed than is available in the current memory chunk, a new memory chunk is allocated. Thus, palloc is the perfect system for small, variable-sized temporary structures that don’t need to live longer than the request.
Another benefit of palloc is that, like the system stack, allocated structures are very close to each other, greatly improving CPU cache locality.
The palloc subsystem in Phusion Passenger 5 is based on the palloc subsystem in Nginx, and further improved. Nginx allocates and destroys a palloc memory chunk on every request. However, Phusion Passenger 5 reuses palloc memory chunks over multiple requests, thereby further reducing memory allocations.
The obvious down side of this technique is that structures, once allocated, are not deallocated until the end of the request. That’s why we use object pooling for mid-sized structures that we know we won’t need at some point (like the HTTP parser object), while we use palloc for everything else besides I/O buffers.
Part 2 is now available: Pointer tagging, linked string hash tables, turbocaching and other Phusion Passenger 5 optimizations
In this blog post we’ve given an introduction into how Ruby app servers work, and we’ve described some of the techniques that we’ve used to make Phusion Passenger 5 fast. But there are a lot more techniques, involving optimized open addressing hash tables; micro-optimization techniques to reduce memory usage and to improve CPU cache locality, like unions and pointer tagging; language-level optimizations like using C++ templates and avoiding virtual functions; linked strings; builtin response caching; etcetera. You can read more about these techniques in part 2 of this blog series.
But despite all the focus so far on performance, Phusion Passenger 5’s strength doesn’t solely lie in performance. Phusion Passenger 5 provides many powerful features, makes administration much easier and lets you analyze production problems more quickly and more easily. In future blog posts, we’ll elaborate on Phusion Passenger 5’s features.
We hope you’ve enjoyed this blog post, and we hope to see you next time!
If you like this blog post, please spread the word on Twitter. :) Thank you.
This blog post is part of a series of posts on how we've implemented Phusion Passenger 5 (codename "Raptor"). You can find more blog posts on the Phusion blog. You can also follow us on Twitter or subscribe to our newsletter. We won't spam you and you can unsubscribe any time.
If the topics in this blog post interest you, then you may want to check out the following literature.

